Building vibestack: how I stopped re-explaining myself to my AI

AWS Community Builder / Cloud Architect / IT Lead / MLOps
A small confession, before anything else
The thing that pushed me to build vibestack was not a strategy meeting. It was a Tuesday evening, and I was tired.
I had spent maybe forty minutes in a Claude Code session walking through a Terraform module - the kind of slow, careful walk where you read the file, then the parent module, then the variable file, then the locals, then a mental diff against what production looks like in the AWS console. After all that, I asked for a small fix. Two lines. And the model, very politely, helped me. And then "improved" three other things I had not asked about.
I closed the laptop. I made tea. I sat down again and looked at the diff. Honestly, the changes were fine. They might even have been good ideas. But they were not what I asked for, and now I had to think about each of them, decide if I trusted them, run tests, and so on. By the time I was done, the small fix had become a thirty-minute review.
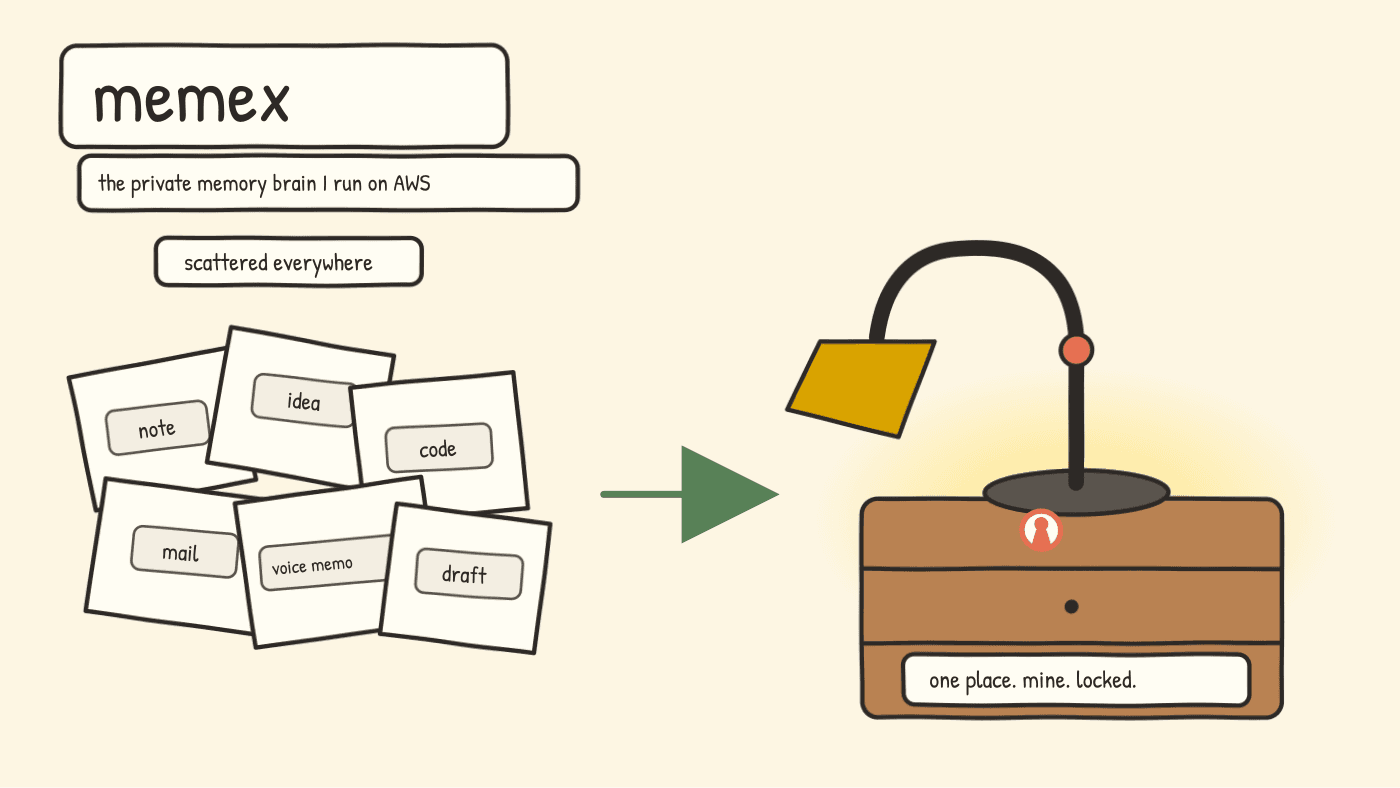
That night I did not write code. I wrote a list. The list said: the next time I sit down with this thing, what would I want it to remember about how I work?
That list became vibestack.
If you have ever finished a session with an AI and felt vaguely unhappy without being able to say why, the next few pages may be familiar.
Why the personal layer matters
The conversation about AI coding tools spends a lot of time on which model to pick, which IDE, which framework. It spends very little time on the layer above all of that - the small, specific, slightly opinionated set of conventions that turns "an AI in your terminal" into "an AI that fits the way this particular work gets done."
That layer is the part of the stack most people skip. It is also the part that makes the difference between collaborating with a useful colleague and shouting instructions at someone who doesn't quite get it. The model is a commodity. The IDE is a commodity. The personal layer is the bit that's actually yours.
vibestack is one shape that layer can take. Forty-four small slash commands, a handful of bash hooks, an install script, and a flat state directory in ~/.vibestack/. The rest of this article walks through what's in there, why each piece exists, and what it has to do with where the industry is heading in 2026.

What vibestack actually is (in one sentence, then several)
vibestack is a personal pack of 44 specialised workflows for Claude Code, exposed as slash commands. That's the elevator version.
The slightly longer version: each workflow is a folder under skills/ with a single SKILL.md file inside it. The file has a small YAML header (the name, what it does, which tools it's allowed to touch, the trigger phrases) and then a body written in plain English. No bash, no DSL - just a careful set of instructions to a smart colleague. Claude Code discovers these files automatically and lets me invoke them as /review, /ship, /investigate, /cso, /freeze, and so on.
That's it, really. The whole repository is around 50 small markdown files, an install script, and a handful of bash hook scripts. There is no framework. There is no SDK. If you delete vibestack tomorrow, Claude Code still works - you just lose 44 small habits I've taught it.
Here are the rough buckets of what's in there:
Planning and product -
/office-hours,/plan-ceo-review,/plan-eng-review,/plan-design-review,/plan-devex-review,/autoplan,/plan-tune. These are the ones I reach for when I want a structured second pair of eyes on something before I write code.Code quality and shipping -
/review,/ship,/investigate,/cso,/pr-summary. The "is this actually good and safe to merge" ones.QA and design -
/qa,/qa-only,/canary,/land-and-deploy,/design-review,/design-html,/design-shotgun,/design-consultation. I spent fifteen years doing infra. Then I built one user-facing product and realised how bad I was at telling typography apart from a polite mess. These are my crutches.Operations and learning -
/retro,/learn,/health,/benchmark,/document-release. These keep me honest week to week.Safety -
/careful,/freeze,/unfreeze,/guard. We'll get to these.Session and context -
/context-save,/context-restore,/setup-memory. The "stop forgetting what we agreed on" ones.Meta-tooling -
/codex,/claude,/benchmark-models,/browse,/open-browser,/pair-agent,/make-pdf,/setup-deploy, and a couple of sillier things.
If that list looks long: yes. It's long because it grew organically over a few months of "I keep doing this thing - let me make it a command." It is not a curriculum. It's a habit pile.
Why I built it instead of using something off-the-shelf
The honest answer is that I tried. I read the awesome-claude-code lists. I copied skills from a few public packs. They were great - and they were not me.
There's a particular kind of friction that hits when your tools are someone else's habits in disguise. A skill that's almost right is sometimes worse than no skill at all, because you don't notice the gap until the wrong thing has already happened. A "review" command that doesn't check the things I actually care about gives me a green light I shouldn't have. A "ship" command that uses a versioning convention I don't follow drags me into manual cleanup.
So I started writing my own. The rule I gave myself early on, written down in a file called ETHOS.md in the repo: if I won't reach for this command at least once a week, it doesn't belong here.
That is also the rule I'd give anyone else thinking of doing this. Don't build a skill pack. Build the five commands you actually use, and let the rest emerge.
The five principles, the way I'd say them out loud
I have these in ETHOS.md and they sound a little serious there. Here they are translated into how I'd say them to a colleague:
1. Write to the model like it's a smart human, not a regex engine. A skill is not a script. If your skill body is full of bash, your skill is wrong - that bash should be in a hook. The body should read like a clear briefing.
2. Search before you build. Half the "new skill" ideas I get are actually existing skills I forgot about, plus a different trigger phrase. Adding more files multiplies confusion. Adding fewer files multiplies clarity.
3. The user is in charge. Always. I don't want a skill that decides for me. I want a skill that surfaces a consequence and lets me decide. /careful warns. /freeze enforces what I told it to enforce. Nothing in vibestack overrides me silently.
4. Hooks are powerful - be quiet with them. A hook intercepts every matching tool call. That is a real footprint. If a skill body would do the job, don't reach for a hook. And if you do, the hook must fail safely. Crash → allow. Don't ever crash → block.
5. Build what you actually use. Skills written speculatively rot. They never get invoked, the trigger phrases drift, and one day you read your own SKILL.md and don't recognise it. Better to delete a skill than to keep one you don't use.
That's it. Five rules. They sound obvious. They're not, until you've built the wrong skill twice.

The part where hooks earn their keep
Let me show you what a hook actually does, because this is the part most people don't see.
Claude Code lets a skill register a hook on certain events. The one I use most is PreToolUse - it fires before the model is allowed to run a tool like Bash, Edit, or Write. The hook is a small script that reads JSON on stdin (the proposed tool call) and writes JSON on stdout (a decision). Three possible decisions:
{}- fine, let it through.{"permissionDecision":"ask","message":"..."}- pause, surface this to me, let me approve or refuse.{"permissionDecision":"deny","message":"..."}- block, don't even ask.
That sounds like nothing. It is the whole game.
Two examples from vibestack.
/careful registers a Bash hook that scans the proposed command. If it matches rm -rf <not node_modules>, DROP TABLE, git push --force, kubectl delete, git reset --hard, and a small list of similar things, it returns ask with a short explanation. I get a chance to look at the thing before I lose the thing. The hook script is around forty lines of bash, mostly safe-listing harmless cases like rm -rf node_modules or dist/ so it doesn't cry wolf.
/freeze is more ambitious. When I run it, I tell Claude "only edit files inside src/api/auth/ for the rest of this session." It writes that path to ~/.vibestack/freeze-dir.txt. From then on, every Edit and Write runs through check-freeze.sh, which compares the proposed file path against the boundary. Outside? Deny. Inside? Allow. The state file is plain text. You can cat it, rm it, edit it. Nothing magic.
Here's a small story about that script that taught me a lesson.
The first version of check-freeze.sh resolved symlinks for the file being edited but not for the boundary itself. That's fine on Linux. On macOS, /tmp is a symlink to /private/tmp. If you froze edits to /tmp/something, then asked to edit /tmp/something/foo.txt, the file path got resolved to /private/tmp/something/foo.txt, which did not start with the boundary /tmp/something/, and the hook denied your own edits. To your own freeze. Inside the directory you said was OK.
The fix is one of the kind I love: a five-line refactor (resolve both sides) and a one-paragraph commit message. It shipped in v1.1.0. And the lesson - apply your transformation to both sides of a comparison, always - is now living rent-free in my head.
The other small fix has the same flavour. The /careful script used \s in a sed regex. macOS BSD sed does not support \s. The fix: use [[:space:]] and anchor with ^. POSIX-portable. Works everywhere. Ten characters of change, hours of "but it works on my colleague's machine" avoided.
These are not exciting fixes. They are the kind of fixes that mean you can rely on the thing.

The other kind of skill: thinking partners
Not every vibestack skill is a hook. Some don't run any bash at all. They're pure markdown - a few thousand words of carefully tuned prose that turn the conversation itself into the tool. Two of them get reached for more than anything else, and they deserve their own section because they do something the rest of vibestack doesn't.

/office-hours - the skill to run before writing a single line
/office-hours opens with one question - what's your goal with this? - and based on the answer it routes into one of two modes.
Startup mode is the hard one. It asks six "forcing questions" designed to expose whether the thing about to be built is real or imaginary:
What's the strongest evidence someone actually wants this - not "is interested," not "signed up for a waitlist," but would be genuinely upset if it disappeared tomorrow?
What are users doing right now to solve this - even badly? What does that workaround cost them?
Name the actual human who needs this. Not a category. A name, a role, a consequence they face if the problem isn't solved.
What's the smallest possible version someone would pay real money for this week - not after the platform is built?
Have you sat down and watched someone use this without helping them? What did they do that surprised you?
If the world looks meaningfully different in three years - and it will - does this become more essential or less?
The skill is direct to the point of discomfort. It refuses to accept polished first answers - it pushes once, then pushes again. It will not let "everyone needs this" pass. It has an explicit anti-pattern list - "interest is not demand," "growth rate is not a vision," "surveys lie, demos are theater" - and it will name the failure mode out loud the moment it spots one. Reading the prompt that drives this skill feels like reading a senior product manager's notebook from after a bad week.
Builder mode is the gentler sibling - same questioning structure, but tuned for side projects, hackathons, learning, open source. The currency there is delight, not demand. What's the coolest version of this? Who would you show this to that would say "whoa"? What would the 10× version look like if there were no time limits?
Both modes produce the same artifact: a markdown design doc, written automatically to ~/.vibestack/projects/<slug>/. Problem statement, demand evidence (or "what makes this cool"), the premises that have been agreed to, two or three alternative approaches, the recommended one, and one concrete next-step assignment. No code. Not even scaffolding. The skill has a hard gate against starting implementation - its only output is the document.
That document then becomes the input to the next skill on this list.
/plan-ceo-review - the dispassionate reread
/plan-ceo-review picks up where /office-hours leaves off. It reads the design doc automatically (or works without one if there isn't one) and reviews the plan in what it calls founder mode - the posture of someone who is not there to rubber-stamp anything.
The skill asks for a mode up front, and there are four:
Scope expansion - dream bigger. What would make this 10× better for 2× the effort? Push scope up, present every expansion as an opt-in.
Selective expansion - hold the line, but cherry-pick wins where they're cheap.
Hold scope - no drift in either direction. Just maximum rigor on what's already there.
Scope reduction - find the minimum viable cut and ship it.
Once a mode is chosen, the skill commits to it. No silent drift halfway through. That single rule is more useful than it sounds - it stops the review from quietly becoming a different review when the conversation gets long.
The body of the review is structured around nine prime directives that read like a grumpy senior engineer's checklist:
Zero silent failures. Every error has a name. Data flows have shadow paths. Interactions have edge cases. Observability is scope, not afterthought. Diagrams are mandatory. Everything deferred must be written down. Optimise for the six-month future. You have permission to say "scrap it and do this instead."
Behind those is a deeper layer - eighteen cognitive patterns borrowed from how strong founders think. Bezos one-way vs. two-way doors. Munger's inversion reflex (for every "how do we win?" also ask "what would make us fail?"). Jobs's subtraction default. Grove's paranoid scanning. None of those are checklist items. They are lenses for reading the plan.
What comes back is the part of the work that is hardest to do for yourself: the dispassionate reread of your own plan, with the quiet failure modes you missed marked in red.
Why these two together
/office-hours and /plan-ceo-review are the part of vibestack that has changed actual output the most. Not because they make code faster - they don't make code at all. They make the right thing get built on the first attempt more often, and that is a much larger lever than any amount of generation speed.
A diff that ships in two days but solves the wrong problem still solves the wrong problem. The most expensive code is the code that gets thrown away after a quarter because nobody asked the six questions before it was written. These two skills are an attempt to keep that from happening.
If only two ideas from this whole article are worth taking, take those.
How vibestack installs itself, and why I'm proud of it
This is going to sound small, but I want to dwell on it because it tells you something about how the whole thing is designed.
The install script does one thing. It walks skills/, finds every SKILL.md, and creates a symlink in ~/.claude/skills/<name>/. Not a copy. A symlink. The canonical source stays in the repo. If I git pull && ./install on Monday morning, every change is immediately live - no rebuild, no sync, no cache to bust.
That decision is not technically clever. It is organisationally clever. It means there is exactly one place where my skills live, exactly one history of how they changed, and exactly zero "I edited the installed copy and lost it on the next pull" moments. I have lost too many afternoons to that pattern in other tools to want to repeat it here.
Hook scripts are also symlinked. State lives in ~/.vibestack/, a flat directory of .txt and .jsonl files I can grep. Nothing about this setup will surprise you in five years. Nothing requires explanation.
Here is the install philosophy in one sentence: the source of truth is the git repo; everything else is a pointer.

The sibling: vibekit
While vibestack lives in ~/.claude/skills/vibestack/, there's a quieter sibling repo over at github.com/timurgaleev/vibekit. It does a different job, and I want to talk about it because the relationship between the two is the actual story.
vibestack is workflows - the slash commands. vibe-config is settings - the always-loaded shape of how Claude Code, Cursor, and Kiro behave when I open a session. Three subfolders, three targets:
vibe-config/claude/ → ~/.claude/
vibe-config/kiro/ → ~/.kiro/
vibe-config/cursor/ → ~/.cursor/
Inside claude/ you'll find the things every session of mine starts with: a CLAUDE.md with my coding philosophy, a rules/ folder with files like language.md, security.md, tests.md, git.md, obsidian.md. There are sub-agent definitions (a planner, a builder, a debugger, a quality reviewer). There's a statusline.py that renders my context window, model, cost, and token usage in the bottom bar. And there's a hooks/vibenotif.py which broadcasts the session state - thinking, working, waiting, done - to a small Electron app and, optionally, to a tiny ESP32 device with an LCD screen that sits on my desk and tells me, in colour, whether the agent needs me.
If that last bit sounds silly, fair enough. It also turns out to be useful. You get up, you make coffee, you glance at the desk on the way back, and you know without opening the laptop whether the agent is grinding or waiting on an answer. A two-dollar screen, doing one thing, doing it well.
The split between vibestack and vibe-config matters. vibestack is the active layer - commands I invoke. vibe-config is the passive layer - guidelines that are always in scope. Mixing them was tempting at first. Keeping them separate has paid off every time I've had to update one without touching the other.
One install command handles vibe-config:
./install.sh # sync everything
./install.sh -n # dry-run, show me what would change
It uses MD5 hashes to diff before writing, so re-running is cheap and idempotent. The same script knows how to disable VibeNotif, how to merge Cursor's cli-config.json without overwriting my personal model preferences, and how to warn me when Cursor's settings.json has drifted on disk. It is the kind of script you only write after the fifth time you have hand-fixed something it should have automated.

Why this matters in 2026, and not in some abstract way
Now the part where I look up from the keyboard.
If you read Anthropic's 2026 Agentic Coding Trends Report - and I think you should, even if you've already read three takes on it - there is one phrase that keeps coming back: context engineering is the load-bearing skill of 2026.
That sentence is doing a lot of work. Translated into something I'd say to a junior engineer over lunch: the bottleneck has moved. It used to be that the model was the bottleneck. The model couldn't write the function, so we wrote it, and the model autocompleted. Now the model can write the function. What it can't do - at least not reliably - is figure out which function you want, in which file, with which conventions, against which constraints, by Thursday. That work has to come from somewhere. Increasingly, it comes from the way you set up the session.
The numbers in the report are striking. Projects with well-maintained context files saw something like 40% fewer agent errors and 55% faster task completion. MCP - Model Context Protocol, Anthropic's spec for connecting tools to models - crossed 97 million installs in March. Skills (SKILL.md files following the universal format) now work across Claude Code, Cursor, Gemini CLI, Codex CLI, and more. Anthropic Academy is running 17 courses and people are showing up for them.
This is what people mean when they say agentic engineering is no longer experimental. The wires have set. The patterns we use today - skills, hooks, MCP, sub-agents, status hooks - are going to be the boring infrastructure of the next decade.
And in that picture, here is the thing I keep thinking about: the most valuable layer is the personal one.
Not because individual taste matters more than team standards. It doesn't. But because the team standards have to be embodied somewhere, and the only place they actually run is on your machine, in your session, against your habits. A team can publish a CLAUDE.md. The CLAUDE.md does nothing until it's loaded. It loads when you set it up. The personal layer is the surface where every other layer lands.
vibestack is mine. It's mine the way my keyboard layout is mine. If you take it as-is, you'll get most of the value of the structure and miss the value of the customisation. The interesting move is not "install vibestack." The interesting move is "fork vibestack, delete half of it, and write three skills that reflect how you actually work."
That's the bit that the trend reports keep almost saying and not quite saying out loud. So I'll say it: start a personal skills pack. It can be five files. It will save you a thousand small re-explanations.

What I'm doing next, and what I'd do differently
A few things are on my list.
I want a /morning-briefing skill that reads my git logs, my Linear tickets (when I'm allowed), and my Obsidian inbox, and gives me a one-page "here is what is on fire" report at 8:30am. Right now I do this by hand. It takes maybe ten minutes. I'd rather it took thirty seconds.
I want to push more learnings into ~/.vibestack/projects/<slug>/learnings.jsonl. The /learn skill already exists, but I haven't been disciplined about it. I'm hoping that as the file fills up, the next conversation about the same project gets sharper. If that doesn't happen, the skill is wrong and I'll redesign it.
I want to write a smaller, opinionated skill template - not a framework, definitely not an SDK - that I can hand to teammates who say "I'd love to set this up but I don't know where to start." Three commands. Maybe four. The minimum viable habit.
If I were starting again from scratch, I would do two things differently. I would write the install script first, before any skill, because almost every regression I hit was an install-time issue. And I would write the hook conventions document before writing any hooks, because I learned the macOS BSD sed lesson the painful way.
These are small regrets. The thing largely works. I use it every day. It saves me time I don't have.
Wrapping up
If there's one thing I'd want you to take away from all of this, it's that the most useful tooling around AI right now isn't the model itself, or the IDE, or even the framework someone wrote a viral blog post about last week. It's the small, specific, slightly opinionated layer you build on top of the rest - the one that knows how you work.
You don't need 44 commands. I didn't start with 44. I started with three. Whatever you build, build it because you keep typing the same thing into the chat window and you're tired of it.
Both repos are MIT-licensed and live on GitHub:
github.com/timurgaleev/vibestack - the slash commands
github.com/timurgaleev/vibekit - the configuration sibling
If something here was useful, or if you've built your own version and want to compare notes, I'd genuinely like to hear about it.
Thanks for reading.
Sources and further reading
Anthropic, 2026 Agentic Coding Trends Report - resources.anthropic.com
Anthropic, Extend Claude with skills - code.claude.com/docs/en/skills
Claude Code: Hooks, Subagents, and Skills - Complete Guide, March 2026 - ofox.ai/blog
A Mental Model for Claude Code: Skills, Subagents, and Plugins, Level Up Coding, March 2026 — levelup.gitconnected.com
Awesome Claude Code — community-curated list — github.com/hesreallyhim/awesome-claude-code
Pento, A Year of MCP: From Internal Experiment to Industry Standard — pento.ai/blog